Experience the cerebras speed advantage
Generate code, summarize docs, or run agentic tasks in real time with the fastest AI inference. Getting started is easy. Download your free API key and go.
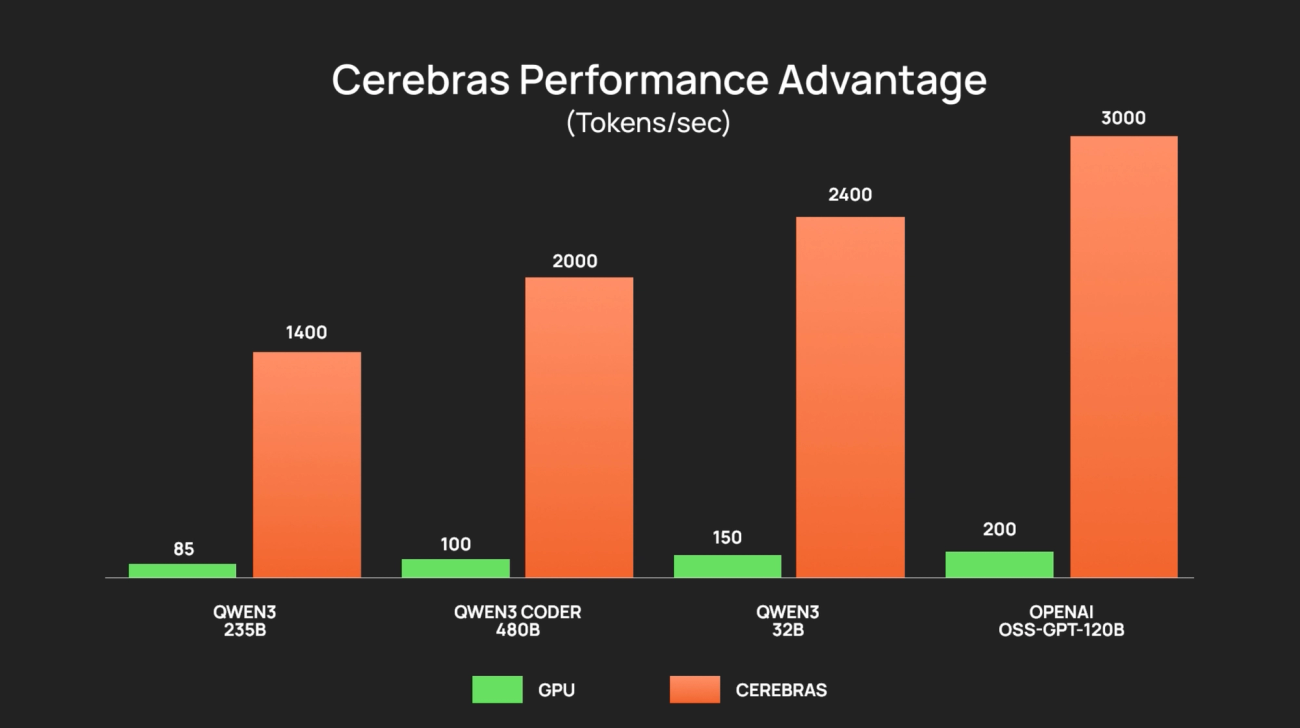

OpenAI gpt-oss-120B on Cerebras
OpenAI’s new open frontier reasoning model gpt-oss-120B runs at 3,000 tokens/sec on Cerebras, delivering the best of GenAI – openness, intelligence, speed, cost, and ease of use – without compromises.
Qwen3 Coder 480B on Cerebras
Qwen3 Coder 480B is among the top coding models, with capabilities on par with Claude 4 Sonnet and Gemini 2.5. On Cerebras, it delivers 2,000+ tokens/sec for instant code generation, refactoring, and inline debugging.
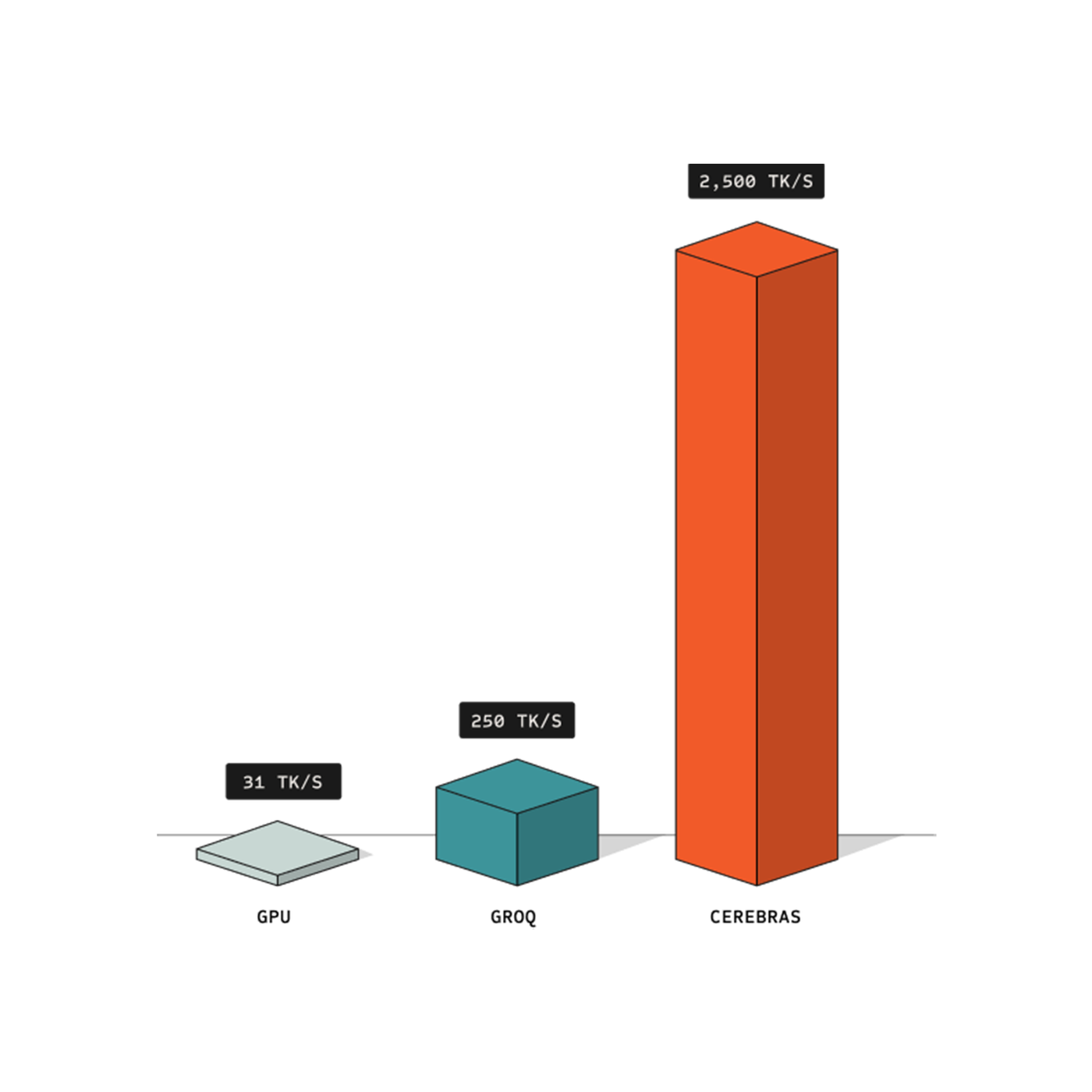
70X Faster than Leading GPUs
With processing speeds exceeding 2,500 tokens per second, Cerebras Inference eliminates lag, ensuring an instantaneous experience from request to response.
High Throughput, Low Cost
Built to scale effortlessly, Cerebras Inference handles heavy demand without compromising speed—reducing the cost per query and making enterprise-scale AI more accessible than ever.

Leading Open Models
Llama 3.1 8B, Llama 3.3 70B, Llama 4 Scout, Llama 4 Maverick, DeepSeek R1 70B Distilled, Qwen 3-32B, Qwen 3-235B and more coming soon.

Real-Time Agents
Chain multiple reasoning steps instantly, letting your agents complete more tasks and deeper workflows.

Instant Code-Gen
Generate full features, pages, or commits in a single shot — no token-by-token delays, zero wait time.

Reasoning in under 1 second
No more waiting minutes for a full answer — Cerebras runs full reasoning chains and returns the final answer instantly.