C-soft
More Innovation in Less Time
With the Cerebras Software Platform, CSoft, focus on deep learning, not distributed optimization.
Train multi-billion-parameter NLP models on a single device without parallel programming. Use existing frameworks or develop custom kernels with flexibility and efficiency.
AI Model Studio
Effortless AI model training
The Cerebras AI Model Studio is a pay-per-model service on dedicated CS-3 clusters, hosted by Cirrascale Cloud. Optimized for large language model training, it delivers deterministic performance with no distributed computing hassles—just push a button and start.

ML Software
Unmatched Productivity and Performance
Easily run PyTorch models on the CS-3 with our lightweight interface. A simple API wrapper integrates via XLA’s lazy tensor backend, optimizing models for the WSE-3 with just a few extra lines of code.

SDK
Designed for flexibility and extensibility
The Cerebras SDK lets developers use wafer-scale computing to speed up their work. With the SDK and Cerebras Software Language (CSL), they can easily develop software kernels using a C-like interface for the WSE's microarchitecture

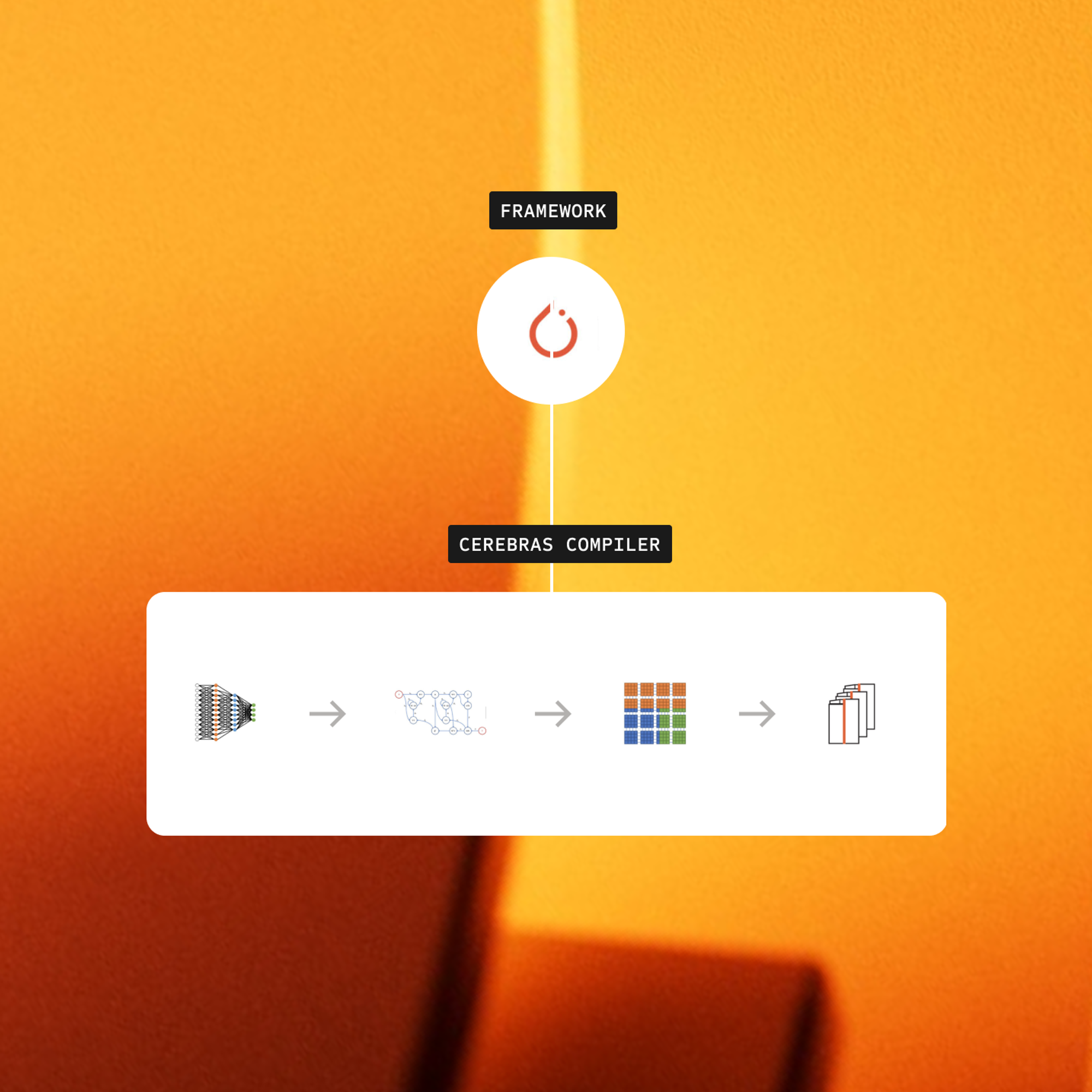
Graph Compiler
Full Hardware Utilization
The Cerebras Graph Compiler (CGC) optimizes your neural network into an executable program, maximizing WSE-3 performance. It intelligently allocates cores and minimizes communication latency for efficient execution.